Redis学习笔记之字符串
本系列是个人的Redis学习笔记,参考的书籍有《Redis设计与实现》、《Redis深度历险--核心原理与应用实践》,Redis源码版本是黄健宏老师注释的Redis-3.0-annotated版本
一、SDS基本概念介绍
Redis有五种基础数据结构,分别是string(字符串)、list(列表)、hash(字典)、set(集合)以及zset(也叫做sorted set,有序集合)。其中,Redis中的字符串采用了一种名为简单动态字符串的类型(simple dynamic string, SDS),而不是C字符串(具体原因后续会解释)。在Redis中,C字符串仅作为字符串字面量,即类似"Hello, world",而在需要使用可修改的字符串的地方,均采用SDS来表示字符串。
当客户端执行命令:
redis> SET name zzk
OK
Redis将在数据库中创建一个新的键值对。其中,键值对的key是一个SDS对象,其中包含着字符串"name";value是一个SDS对象,内部包含着字符串“zzk”。
又如,当客户端执行如下命令:
redis> LPUSH classmates xiaoming xiaohong xiaobai
Redis将在数据库中创建一个键值对,其中,key是一个包含着字符串"classmates"的SDS对象,value是一个list对象。这个list对象有三个元素,每个元素都是一个SDS对象,第一个SDS对象包含字符串"xiaoming",第二个SDS对象包含字符串"xiaohong"等。
从上述例子可以看出,SDS作为Redis的字符串实现,被频繁用在各种使用场景。
二、为什么使用SDS而不是C字符串?
以下涉及的Redis代码来自Redis3.0,虽然Redis目前已经更新到7.0,但是数据结构的实现原理是一脉相承的,3.0版本的代码更加简单,有助于原理的理解。
SDS的结构定义如下:
struct sdshdr {
int len;
int free;
char buf[];
};
其中,buf是一个字符数组,用于保存字符串;len用于记录buf数组中已使用字节的数量,也就是SDS所保存的字符串的长度;free用于记录buf数组中未使用字节的数量。
下图表示一个包含字符串“zzk”的SDS对象。
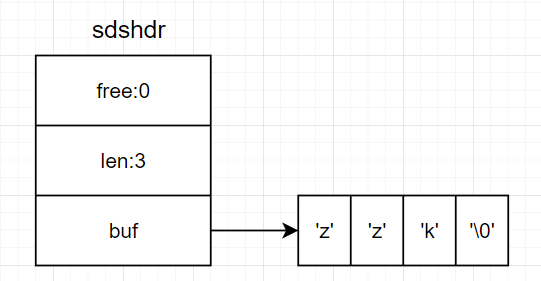
在这个SDS对象中,buf是一个char数组,其数组内容为:'z','z','k'和末尾的'\0'。free为0表示没有多余的字节可供使用,len为3表示这个SDS的字符串长度为3(与C字符串长度定义一样,不包括末尾的'\0')
下图展示了另一个SDS对象的内部结构:
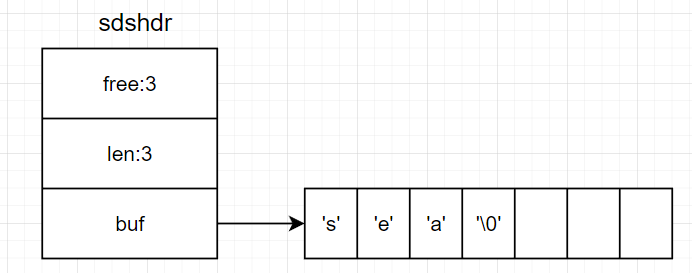
在这个SDS对象中,buf数组的内容为"sea"(末尾还有个'\0'),len为3表示这个SDS的字符串长度为3,而free为3表示这个buf数组还有3个字节未被使用。
1. 常数时间获取字符串长度
从上述两个例子可以看出,buf数组的实际大小并不总是等于(字符串长度+1)。
而在C语言中,一个C字符串例子如下:
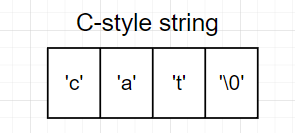
可以看出,C字符串并不包含长度信息,当需要获取字符串长度信息时,需要遍历一遍字符串才能计算出其长度,时间复杂度为$O(n) $,n为字符串长度。(题外话:strlen()是求C字符串长度函数,有时候编程不注意,还可能将strlen()写到循环判断条件中,造成复杂度提升一个量级)
因此,追求效率的Redis并没有直接采用C字符串作为字符串实现,而是使用了len来记录当前使用的字符大小,从而将时间复杂度降低到$O(1)$。
2. 防止缓冲区溢出
如果使用不当,C字符串还可能带来缓冲区溢出的问题。
假设如下情况,有两个C字符串s1和s2,他们的空间分配位置如下,s2紧挨在s1后面。
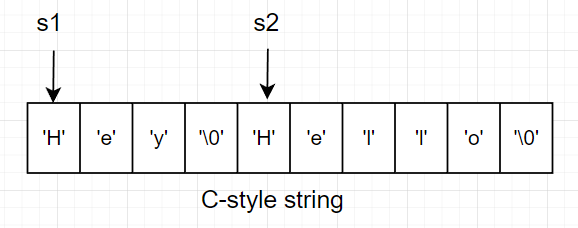
若直接调用C函数strcat(s1, ",Lucy"),企图将s1的内容修改为"Hey,Lucy",这样做确实能达到目的。然而,这种方式是错误的,正确的方式应该是在调用strcat()之前为s1分配足够的空间,而不是不经检查地直接调用。因为这种方式会导致s2被覆盖,称之为缓冲区溢出现象,如下图所示:
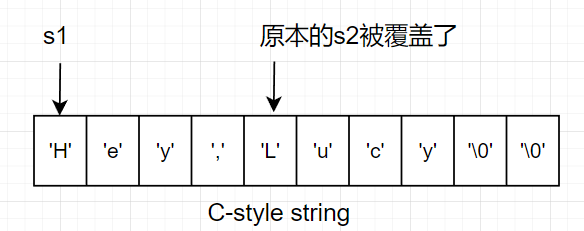
而SDS的设计则避免了这一情况。当需要对SDS进行扩充时,SDS中的free属性使得SDS的API很容易检查SDS的剩余空间是否满足修改的需要,如果不满足的话,会为SDS分配一个新的容量足够的buf数组,再去执行修改操作。因此,SDS的使用者不需要手动修改SDS空间大小,也不用担心出现缓冲区溢出问题。
3. 提高内存重分配效率
如前所述,C字符串本身并不保存自身的长度信息,而是通过在字符串末尾添加一个'\0'来标识字符串结束。因此,对于一个包含了 N 个字符的 C 字符串来说, 这个 C 字符串的底层实现总是一个 N+1 个字符长的数组(额外的一个字符用于保存'\0'字符)。
这种关联性使得对C字符串的增加或者删除字符操作总是伴随着内存重分配操作。
仍以C字符串的拼接场景为例,若要在值为“hello”的字符串s1后面拼接上“,world”,那么在调用strcat(s1,",world");操作之前,需要先为s1分配足够大的空间,否则就会发生缓冲区溢出。
若之后我们想在s1之后在拼接上"!!!",那么在调用strcat(s1,"!!!");操作之前又需要为s1分配空间。
这种频繁分配空间的方式会带来性能开销,而Redis作为高性能的缓冲中间件,若是采用这种方式则必然对性能造成影响。
因此,SDS采用了空间预分配方式来解决这一问题。在 SDS 中, buf 数组的长度不一定就是实际存储的字符数量加一, 数组里面可以包含未使用的字节, 而SDS 的 free 属性记录了这些字节的数量 。
4.SDS的空间预分配策略
空间预分配策略用于优化 SDS 的字符串增长操作: 当 SDS 的 API 对一个 SDS 进行修改, 并且需要对 SDS 进行空间扩展的时候, 程序不仅会为 SDS 分配修改所必须要的空间, 还会为 SDS 分配额外的未使用空间。
其中, 额外分配的未使用空间数量由以下规则决定:
- 如果对 SDS 进行修改之后, SDS 的长度 len 小于 1 MB , 那么程序分配和 len 属性同样大小的未使用空间, 这时 SDS len 属性的值和 free 属性的值相同。 举个例子, 如果进行修改之后, SDS 的 len 将变成 10 字节, 那么程序也会分配13 字节的未使用空间, SDS 的 buf 数组的实际长度将变成 10+ 10 + 1 = 21 字节(额外的一字节用于保存'\0'字符)
- 如果对 SDS 进行修改之后, SDS 的长度将大于等于 1 MB , 那么程序会分配 1 MB 的未使用空间。 举个例子, 如果进行修改之后, SDS 的 len 将变成 10 MB , 那么程序会分配 1 MB 的未使用空间, SDS 的 buf 数组的实际长度将为 10 MB + 1 MB + 1 byte 。
第一条规则简单地说就是成倍增长规则,只不过这个基数是修改之后的长度。第二条规则是因为Redis需要在性能和效率之间取舍,如果达到了1MB的级别还是采用成倍增长规则,那么SDS的增长速度很快导致大量的内存空间占用。
通过这种预分配策略, SDS 将连续增长 N 次字符串所需的内存重分配次数从必定 N 次降低为最多 N 次。
此外,SDS还采用了惰性空间释放方式。
所谓惰性空间释放是指, 当 SDS 的 API 需要缩短 SDS 保存的字符串时, 程序并不立即使用内存重分配来回收缩短后多出来的字节, 而是使用 free 属性将这些字节的数量记录起来, 并等待将来使用。也就是说,惰性空间释放用于优化 SDS 的字符串缩短操作。
例如, sdstrim 函数接受一个 SDS 和一个 C字符串作为参数, 从 SDS 左右两端分别移除所有在 C字符串中出现过的字符。
执行sdstrim(s, "AA..");后SDS的结构变化如下图所示:
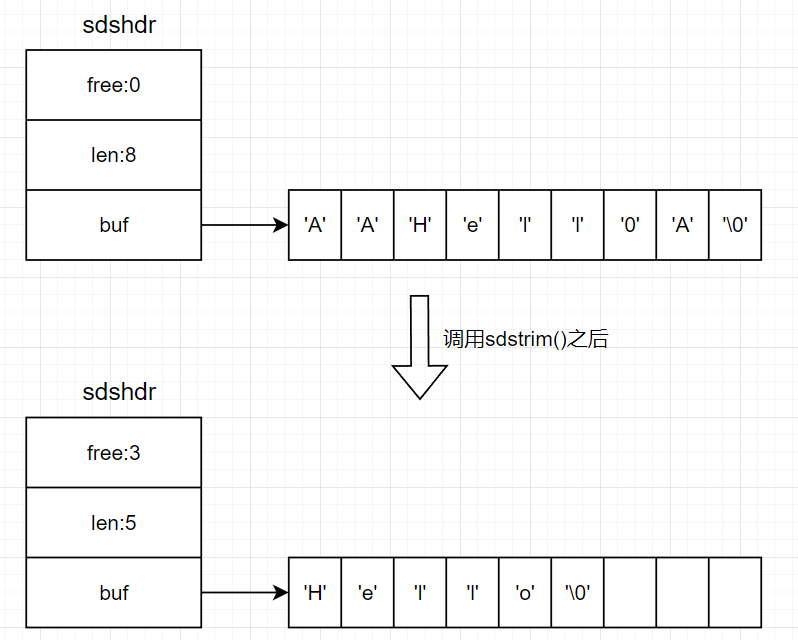
可以看到,并没有回收三个'A'字符所占的空间,而是使用free记录了剩余空间。
当在下一次对SDS进行修改操作,比如调用strcat(s, "zzk")时,不必在进行内存重分配,因为有足够的剩余空间支持拼接操作,结果如下所示:
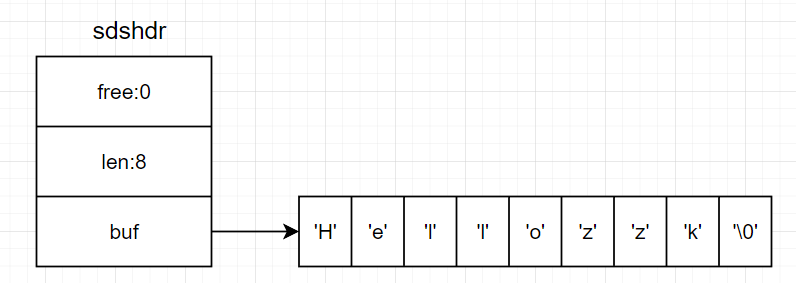
5.二进制安全
此外,在C字符串中,由于只使用'\0'来表示字符串结束,因此,一个字符串里面不能包含空字符,否则就会被认为是字符串结尾。这就使得C字符串只能存储文本数据,而不能存储二进制数据如图片、视频等。
而Redis的SDS则可以用来存储二进制数据,SDS不靠空字符来标识存储内容的结束,而是通过len来标识。buf[]数组是一个char数据,可以直接用于存储二进制数据(只需要定义好编解码格式即可进行读写)。
当然,另一方面,SDS也会在字符串末尾添加'\0',因此SDS也可以复用部分C字符串函数。